لا يعمل البحث المدعوم بالذكاء الاصطناعي على مخطط واحد. نعم، تعتمد معظم المنصات على مزيج ما من استرجاع المتجهات، ونماذج الترتيب، ومخرجات النماذج اللغوية الكبيرة، ولكن الطريقة التي تجمع بها هذه الأجزاء معًا يمكن أن تبدو مختلفة تمامًا. تشكل هذه الاختلافات كل شيء بدءاً من السرعة إلى الشفافية إلى مدى فائدة الإجابات.
بالنسبة لأي شخص يعمل في مجال تحسين المحرك التوليدي (GEO)، فإن فهم هذه الفروق ليس أمرًا اختياريًا. ما يجعل المحتوى الخاص بك يظهر داخل ميزات الذكاء الاصطناعي في جوجل قد لا يسجل على الإطلاق في بيربليسيتي أو بينج، والعكس صحيح. إن معرفة الآليات الكامنة وراء كل نظام هو الخطوة الأولى لجعل المحتوى الخاص بك قابلاً للاكتشاف.
تلقي هذه المقالة نظرة فاحصة على بنية اللاعبين الأكثر ظهورًا. سنفحص كيف يبنون خطوط الأنابيب الخاصة بهم، والخيارات التي يتخذونها حول الفهرسة والتركيب، وما تعنيه هذه الخيارات بالنسبة لظهور علامتك التجارية.
لماذا يعتبر الجيل المعزز للاسترجاع مهمًا
إن العمود الفقري لأدوات البحث بالذكاء الاصطناعي اليوم هو تصميم يُعرف باسم التوليد المعزز للاسترجاع، أو RAG. وهو في الأساس طريقة لإصلاح اثنين من أكبر العيوب في النماذج اللغوية: عادة اختلاق الأشياء وحقيقة أن بيانات التدريب الخاصة بهم تصبح قديمة. من خلال ربط التوليد بمصادر حية أو محدثة بشكل متكرر، يساعد RAG في الحفاظ على دقة الإجابات وملاءمتها.
عادةً ما تتكشف العملية على النحو التالي: يأخذ النظام سؤال المستخدم ويحوّله إلى ناقل كثيف واحد أو أكثر. تتم مقارنة هذه المتجهات مع فهرس التضمينات المخزنة التي تمثل المحتوى عبر التنسيقات: نص أو فيديو أو صور أو حتى بيانات منظمة. يقوم النظام بعد ذلك بسحب مجموعة مرشحة من التطابقات. قبل تمريرها إلى نموذج اللغة، غالبًا ما يقوم مُصنّف أكثر ثقلًا من حيث الموارد بإعادة ترتيب تلك المرشّحات حسب الصلة. تصبح الشرائح العليا من تلك المجموعة هي السياق الأساسي لاستجابة النموذج.
الميزة واضحة: فبدلاً من السحب من بيانات التدريب التي مضى عليها أشهر فقط، يمكن للنموذج أن يستند إلى المعلومات التي تم جلبها قبل لحظات. بالنسبة لمحترفي GEO، هذا يعني أن الرؤية تنحصر في أمرين. أولاً، يجب أن يكون المحتوى الخاص بك قابلاً للعثور عليه في مساحة التضمين من خلال البيانات الوصفية الغنية والإشارات الدلالية الواضحة. ثانياً، يجب أن يكون مكتوباً بطريقة يمكن للنموذج استيعابها بسهولة: منظمة، وواقعية، ونظيفة. إذا فاتك أي من الشرطين، فلن يصل المحتوى الخاص بك إلى الإجابة النهائية التي تم إنشاؤها.
الفهرسة الدلالية كأساس
اعتمدت محركات البحث التقليدية على الفهارس المقلوبة التي تطابق الكلمات الدقيقة. يقلب البحث القائم على الذكاء الاصطناعي هذا النموذج من خلال تخزين المعلومات كمتجهات كثيفة داخل قاعدة بيانات. لا يتم تمثيل كل مستند من خلال الكلمات المفتاحية وحدها، ولكن من خلال أنماط رقمية تلتقط معناها في فضاء عالي الأبعاد. لهذا السبب يمكن أن يظل الاستعلام والمقطع مترابطين حتى لو لم يشتركا في كلمة واحدة مشتركة.
تميل الأنظمة الحديثة أيضًا إلى الفهرسة متعددة الوسائط. فبدلاً من التعامل مع النص كنقطة الدخول الوحيدة، فإنها تنشئ تضمينات للصور والصوت والجداول وغيرها من التنسيقات، وكلها مرتبطة بمعرف مستند واحد. عملياً، هذا يعني عملياً أن رسماً بيانياً أو صورة منتج على موقعك يمكن أن تظهر كدليل في إجابة مولّدة، حتى لو لم يكن النص المحيط بها منافساً.
بالنسبة إلى GEO، فإن الدرس المستفاد واضح ومباشر: الوضوح الدلالي هو الفائز. يجب أن يوضح المحتوى الأفكار بلغة واضحة، وليس دفنها في المصطلحات. تحتاج الصور إلى نص بديل وتعليقات توضيحية ذات مغزى. يجب أن يحتوي الصوت والفيديو على نصوص وبيانات وصفية تصف ما بداخله. وكلما كانت إشاراتك أكثر ثراءً ووضوحًا، كلما كانت فرصتك أفضل في أن يتم جذبك إلى طبقة الاسترجاع.
المزج بين الاسترجاع المعجمي والدلالي
على الرغم من أن البحث المتجه قد غيّر قواعد اللعبة، إلا أن معظم أنظمة البحث بالذكاء الاصطناعي لا تعتمد عليه وحده. فهي تستخدم نهجًا هجينًا يجمع بين نقاط القوة في كل من الاسترجاع الدلالي والاسترجاع التقليدي القائم على الكلمات الرئيسية.
لا تزال الأساليب المعجمية تتألق عندما تكون هناك حاجة إلى الدقة - فكر في المصطلحات النادرة أو معرّفات المنتجات أو الأسماء الدقيقة. من ناحية أخرى، تتفوق الأساليب الدلالية في التقاط المعنى الأوسع، وإظهار المحتوى الذي قد لا يتطابق كلمة بكلمة ولكنه يتوافق مع القصد. من خلال تشغيل كلا النهجين جنبًا إلى جنب ثم تطبيق أداة إعادة الترتيب لتحسين النتائج، يمكن للمنصات الحصول على أفضل ما في العالمين.
من الناحية العملية، يبدو هذا في كثير من الأحيان مثل بحث عن الكلمات المفتاحية BM25 يعمل جنبًا إلى جنب مع بحث عن متجه أقرب جار. يتم دمج المخرجات وتطبيعها وإعادة ترتيبها من خلال نموذج سياقي يوازن بين الصلة على مستوى المقطع. والنتيجة هي مجموعة من النتائج التي توازن بين الدقة والاستدعاء.
بالنسبة لمتخصصي GEO، فإن الخلاصة واضحة: لا يمكنك التخلي عن الأساسيات. لا يزال التحسين التقليدي للكلمات الرئيسية مهمًا للمطابقة المعجمية، بينما تحدد التغطية الدلالية ما إذا كنت ستظهر في فهرس التضمين أم لا. يأتي النجاح من القيام بكليهما بشكل جيد، وليس اختيار أحدهما على الآخر.

كيف نتعامل مع توقعات البيئة العالمية في نوبتيما
في نوبتيمافإننا ندرك أن البحث قد تغير. لم يعد الأمر يتعلق فقط بتسلق الروابط الزرقاء - بل أصبح الأمر يتعلق بالظهور في بيئات مدعومة بالذكاء الاصطناعي حيث يتم إنشاء الإجابات وليس فقط إدراجها. لهذا السبب قمنا ببناء نهجنا حول كل من الأسس الكلاسيكية لتحسين محركات البحث والاستراتيجيات المصممة خصيصًا للبحث التوليدي.
إليك كيف نجعلها تعمل
- تحسين محركات البحث SEO + GEO معًا: نحن نتعامل مع كل شيء بدءًا من عمليات التدقيق الفني وإصلاحات الموقع إلى استراتيجيات المحتوى المصممة للظهور في استعراضات الذكاء الاصطناعي وBing Copilot وBerplexity.
- نتائج قابلة للقياس: لقد جمع عملاؤنا مجتمعين أكثر من $500 مليون دولار أمريكي، مع متوسط عائد 3.2 أضعاف على الإنفاق الإعلاني ونمو متسق في عدد الزيارات عبر القطاعات التنافسية.
- محتوى كبير الحجم وعالي الجودة: نحن ننشر أكثر من 800 ألف كلمة شهرياً، ونمزج بين الرؤى القائمة على الذكاء الاصطناعي والتحرير البشري المتخصص حتى يكون المحتوى قابلاً للقراءة الآلية وجذاباً للأشخاص الحقيقيين.
- انتشار عالمي: يضمن عملنا في مجال تحسين محركات البحث الدولية قدرة العلامات التجارية على التوسع عبر اللغات والمناطق مع وجود الهيكل والبيانات الوصفية الصحيحة.
- ثقة مثبتة: أكثر من 70 من رواد الصناعة يعتمدون علينا في تحقيق النمو المستدام، وليس فقط المكاسب قصيرة الأجل.
تركيزنا بسيط: نقوم بهندسة الملاءمة. من خلال جعل المحتوى واضحًا ومنظّمًا وموثوقًا، نساعد العلامات التجارية على كسب مكانتها في الإجابات التي تولدها منصات الذكاء الاصطناعي - والبقاء فيها مع تطور مشهد البحث.
بحث Google بالذكاء الاصطناعي: نظرة عامة ووضع الذكاء الاصطناعي
يعتمد دخول Google في مجال البحث التوليدي مباشرةً على بنيتها الأساسية طويلة الأمد، حيث تمزج نماذج لغوية كبيرة مع أنظمة البحث التي صقلتها لعقود. فبدلاً من التعامل مع إجابات الذكاء الاصطناعي كميزة إضافية، قامت Google بدمجها في جوهر البحث.
عندما تكتب استعلامًا، لا يقوم جوجل بإجراء بحث واحد فقط. فهو يقسّم الاستعلام إلى عدة زوايا - أشكال مختلفة تجسّد المقاصد المحتملة المختلفة. يتم إرسال هذه الاستعلامات العرضية عبر مصادر متعددة في آنٍ واحد: فهرس الويب الرئيسي، والرسم البياني المعرفي، ونصوص يوتيوب، وموجزات التسوق، وقواعد البيانات المتخصصة الأخرى.
يتم تجميع النتائج من كل مصدر وتصفيتها واستخلاصها قبل تسليمها إلى نموذج قائم على الجوزاء. في النظرة العامة للذكاء الاصطناعي، يقوم النموذج بتجميع ملخص موجز ووضعه في أعلى صفحة النتائج مع اقتباسات منسوجة. في وضع الذكاء الاصطناعي، تتحول التجربة إلى تدفق محادثة، حيث يستمر السياق عبر المنعطفات ويمكن للنظام طلب معلومات إضافية في منتصف المناقشة.
بالنسبة لـ GEO، فإن التأثير كبير: يكافئ جوجل المحتوى الذي يمكن أن يلبي زوايا متعددة للاستعلام. إذا كانت صفحتك تغطي شريحة واحدة فقط، فإنك تخاطر بأن يتم استبعادك. الصفحات التي تعالج المقاصد ذات الصلة، وتقدم مقاطع واضحة ومستقلة بذاتها، وتظهر السلطة تحظى بفرصة أفضل بكثير للظهور في التوليف.
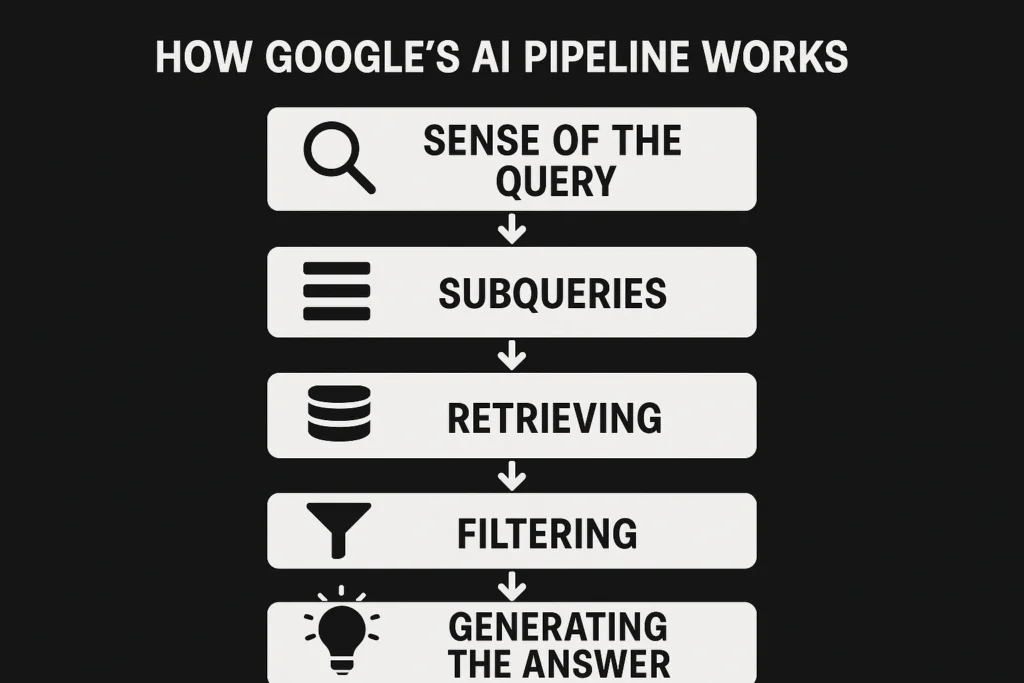
كيف يعمل خط أنابيب الذكاء الاصطناعي من جوجل خلف الكواليس
على الرغم من أن الواجهة تبدو جديدة، إلا أن "نظرة عامة على الذكاء الاصطناعي" و"وضع الذكاء الاصطناعي" من Google مدعومان بعمليات مدمجة في عمق حزمة البحث. واستناداً إلى ما هو مرئي من براءات الاختراع والتصريحات العامة والسلوك الملاحظ، يبدو أن النظام يتبع خمس مراحل رئيسية:
1. فهم الاستعلام
الخطوة الأولى هي تحليل الاستعلام بطرق متعددة. يُنشئ Google تمثيلات مختلفة: نسخة معجمية للمطابقة الدقيقة للكلمات، وتضمينات كثيفة لاسترجاع الدلالات، وكيانات تم تعيينها مقابل الرسم البياني المعرفي، وإشارة مهمة تحدد نوع الإجابة المطلوبة - مقارنة أو كيفية أو ملخص. كما يتعامل أيضًا مع الأساسيات مثل اكتشاف اللغة والتصحيحات الإملائية. ليس كل استفسار مؤهلاً لإجابة الذكاء الاصطناعي؛ فغالباً ما يتم تصفية عمليات البحث الحساسة أو عالية المخاطر.
2. التوسيع باستخدام الاستعلامات الفرعية
إذا كان الاستعلام مؤهلاً، يقوم جوجل بتجزئته إلى استعلامات فرعية متعددة مصممة لالتقاط القصد الخفي.
خذ الاستعلام "كيف تبدأ حديقة خضروات في المنزل" كمثال. يمكن أن يتفرع إلى
- "نصائح لزراعة الخضروات للمبتدئين"
- "تقويم زراعة الخضروات حسب الموسم"
- "أفضل تربة لحدائق الخضروات"
- "الأدوات اللازمة للبستنة المنزلية"
يتم توجيه كل استعلام فرعي إلى المصدر الأكثر صلة، سواء كان ذلك فهرس الويب أو نصوص يوتيوب أو موجزات التسوق أو الخرائط.
3. الاسترجاع من مصادر متعددة
يتم تشغيل كل استعلام فرعي من خلال محرك الاسترجاع المناسب. بالنسبة لنتائج الويب، قد يعني ذلك مطابقة الكلمات الرئيسية BM25 إلى جانب البحث الدلالي القائم على المتجهات. وتعتمد مصادر أخرى على طرق مختلفة - اجتياز الرسم البياني لحقائق الرسم البياني المعرفي، والتضمينات متعددة الوسائط لمقاطع الفيديو أو الصور. غالبًا ما يتم تقسيم المستندات إلى أجزاء أصغر مع التضمينات الخاصة بها، مما يحسن الاسترجاع على مستوى أكثر دقة.
4. الدمج والتصفية
يتم تجميع النتائج التي تم إرجاعها معًا وإزالة التكرارات وتطبيق الفلاتر. ينظر Google في إشارات الثقة (E-E-A-T)، والحداثة، والتحقق من السلامة، وما إذا كانت المقاطع نظيفة بما يكفي ليتم اقتباسها مباشرةً. إذا لم يتمكّن النظام من العثور على مقتطفات قابلة للاستخراج، فمن غير المرجح أن يتم الاستشهاد بهذه الصفحات، حتى لو كانت ذات صلة.
5. توليد الإجابة
أخيرًا، يأخذ النموذج المستند إلى الجوزاء المقاطع العليا وينسجها في استجابة مركبة. قد تظهر الاستشهادات مضمنة أو في لوحات جانبية أو كقوائم مصادر قابلة للتوسيع. تهدف النظرة العامة للذكاء الاصطناعي إلى الحصول على ملخصات موجزة أحادية المقطع، بينما يسمح وضع الذكاء الاصطناعي بإجراء محادثات أطول ومتعددة الأدوار، واسترجاع المزيد من الأدلة حسب الحاجة.
ما يعنيه ذلك بالنسبة إلى GEO: يعتمد النجاح على تغطية العديد من المقاصد ذات الصلة، وكتابة مقاطع قائمة بذاتها كإجابات واضحة وقابلة للاستخراج، والإشارة إلى السلطة. الصفحات التي تستوفي هذه المعايير لديها فرصة أفضل بكثير للظهور والاستشهاد بها في نتائج الذكاء الاصطناعي في جوجل.
ChatGPT: نموذج بدون فهرس خاص به
على عكس Google أو Bing، لا يحتفظ ChatGPT بفهرس ويب دائم خاص به. يتم تدريب النموذج الأساسي على مجموعة بيانات ضخمة ومجمدة، ولكن عندما يتم تمكين التصفح فإنه يعتمد على الاسترجاع المباشر. عندما يطرح المستخدم سؤالاً ما، يقوم ChatGPT بإعادة صياغته إلى استعلام على غرار البحث ويرسله عبر محركات خارجية، غالباً Bing وأحياناً Google. ومن هناك، يسترجع مجموعة من الروابط، ويجلب المحتوى في الوقت الفعلي، ويعالج تلك المواد مباشرةً لبناء إجابته.
هذا الإعداد له عواقب مهمة. فظهور المحتوى الخاص بك لا علاقة له بالسلطة التاريخية أو الترتيب على المدى الطويل. إنه يعتمد كليًا على ما إذا كان يمكن استرداد صفحاتك وتحليلها في لحظة إجراء الاستعلام. إذا كان موقعك محجوبًا في robots.txt، أو كان محجوبًا بسبب بطء التحميل، أو كان مخفيًا خلف العرض من جانب العميل، أو مكتوبًا بطريقة مبهمة جدًا بحيث لا يمكن للنموذج تحليلها، فلن يصل إلى مرحلة التوليف على الإطلاق.
بالنسبة للظهور في هذه البيئة، تبدو قواعد اللعبة أقرب إلى أساسيات تحسين محركات البحث الكلاسيكية. يجب أن تكون الصفحات خفيفة الوزن وقابلة للزحف إليها تقنيًا وشفافة من الناحية الدلالية. وهذا يعني عمليًا: HTML نظيفًا، وأداءً سريعًا، وعدم وجود حواجز أمام برامج الزحف، ومحتوى مكتوب بلغة بسيطة قابلة للاستخراج. عندما يصل النموذج إلى السياق في الوقت الفعلي، فهذه هي المواقع التي يمكنه استخدامها بالفعل.
Bing Copilot من Bing Copilot: البحث يلتقي بالذكاء الاصطناعي التوليدي
يُظهر برنامج Bing's Copilot ما يحدث عندما يتم دمج محرك بحث ناضج مع نموذج محادثة. فبدلاً من التخلص من عقود من أنظمة التصنيف، أعادت مايكروسوفت استخدام فهرس Bing ثم أضافت طبقة على غرار GPT لتلخيص النتائج. ويتمثل التأثير في أن جميع أساسيات تحسين محركات البحث المألوفة لا تزال تحدد الصفحات التي تصل إلى مجموعة الصفحات، بينما يحدد الوضوح والبنية الصفحات التي يتم الاستشهاد بها بالفعل في الإجابات.
إليك كيفية سير خط الأنابيب عادةً.
الخطوة 1: تفسير ما طلبته
عندما يأتي استعلام، لا يقوم Copilot بقراءته في ظاهره فقط. فهو ينشئ تفسيرات متوازية متعددة: واحد لمطابقة الكلمات المفتاحية التقليدية، وواحد للتشابه الدلالي عبر التضمينات، وآخر يعيّن الكيانات إلى الرسم البياني المعرفي ل Bing. كما يقوم أيضًا بوضع علامة على الهدف من الطلب: سواء كان بحثًا عن حقائق، أو دليل إرشادي، أو مقارنة منتجات، ويستخدم هذه الإشارة لتحديد المصادر الرأسية التي يجب الاعتماد عليها. على عكس عادة Google في نشر الاستعلامات على نطاق واسع، فإن Bing يبقي الأمور أكثر إحكامًا، ويقوم بالتصفية في وقت مبكر.
الخطوة 2: المزج بين الكلمات الرئيسية والمطابقات الدلالية
يقوم Copilot بتشغيل كل من البحث بالمطابقة التامة والبحث الدلالي جنبًا إلى جنب. تعمل مطابقة الكلمات المفتاحية بشكل أفضل مع المعرّفات الفريدة مثل وحدات حفظ المخزون أو أسماء العلامات التجارية، بينما يسحب البحث الدلالي المقاطع ذات الصلة المفاهيمية. يتم مزج النتائج وتطبيعها وتصفيتها للتأكد من حداثة وجودة الموقع. ونظرًا لأن فهرس Bing منسق بالفعل، فإن ما يأتي من خلال الفهرس يميل إلى أن يكون قويًا وقابلًا للزحف وقانونيًا. هذا هو السبب في أن النظافة البسيطة: الإشارات الأساسية الواضحة، وأوقات التحميل السريعة، و HTML النظيف، لا تزال مهمة جدًا هنا.
الخطوة 3: اختيار المقاطع المناسبة
في هذه المرحلة، يطبق Bing أداة إعادة تصنيف أكثر تقدمًا تنظر إلى الاستعلام والمقطع معًا. لم يعد يتعامل مع الصفحات على أنها متجانسة؛ وبدلاً من ذلك، يقوم بتسجيل المقاطع الفردية. يفضل النموذج المقاطع الموجزة والمحددة النطاق وسهلة إعادة الاستخدام - تعريف أو شرح قصير أو كتلة منظمة مثل جدول. يبدأ التكرار هنا أيضًا، حيث يتم إزالة المحتوى شبه المتطابق وضمان التنوع. الثقة والسلطة مهمان في فواصل التعادل، لذا فإن المقطع المنظم بشكل جيد من مجال حسن السمعة يتفوق على نفس الفكرة من موقع أضعف.
الخطوة 4: تحويل المقاطع إلى إجابة
يتم تسليم المقاطع العلوية إلى نموذج من فئة GPT، والذي يولد ملخصًا يستند إلى تلك الأدلة. إن توليد Copilot مقيد بإحكام: فهو مصمم لإعادة الصياغة والتوليف، وليس للاختراع. في المحادثات الأطول، يمكن أن يستدعي استرجاعًا إضافيًا عندما تظهر زوايا جديدة، لكن النمط العام يبقى مرتكزًا على ما تم استرجاعه بالفعل. بالنسبة لمالكي المواقع، هذا يعني أن أفضل رهان لك هو صياغة المطالبات بشكل واضح ونطاق، بحيث يمكن للنموذج رفعها دون التلاعب بأجزاء متعددة.
الخطوة 5: عرض النتائج وتمكين الإجراءات
بمجرد اكتمال التوليف، يقدم Copilot الإجابة مع الاقتباسات المرفقة. وغالبًا ما تظهر هذه الاقتباسات على شكل نصوص مضمنة أو قوائم قصيرة أسفل الإجابة. وخلافاً للنظرات العامة الأوسع نطاقاً في Google، يميل Copilot إلى إبقاء قائمة الاقتباسات صغيرة ودقيقة، حيث أن التأصيل يحدث على مستوى المقطع. ما يميزه هو تكامله العميق مع Microsoft 365: يمكن أن تنتقل الإجابات مباشرةً إلى Word أو Excel أو Teams. وهذا يجعل التنسيقات المنظمة: الجداول، والقوائم، وقوائم المراجعة، قوية بشكل خاص، لأنها تتدفق بسلاسة إلى سير عمل المستخدم.
لماذا لا تنجح الصفحات في بعض الأحيان
قد يتم تصنيف صفحة ما في نتائج Bing القياسية ولكن لا تظهر أبدًا في اقتباسات Copilot. الأسباب المعتادة ليست موضوعية، ولكنها هيكلية: بطء العرض من جانب العميل الذي يؤخر النص، أو تخطيطات الصفحة المزدحمة التي تربك الاستخراج، أو امتدادات طويلة من السرد التي تخفي الادعاء الرئيسي. يمكن أن تضر إشارات المؤلف أو الكيان الضعيفة أيضًا عندما تكون المقاطع المتنافسة متساوية.
تتمثل طريقة عمل GEO لـ Bing Copilot في التفكير في تحسين محركات البحث التقليدية بالإضافة إلى هندسة مستوى المرور:
- تنافس على كل من الاسترجاع المعجمي والدلالي.
- تقديم المطالبات في مقاطع قصيرة وقابلة للاستخراج.
- تعزيز إشارات الكيان والمؤلف.
- حافظ على تحديث الصفحات بمحتوى محدث أو مؤرخ.
- تقديم المحتوى بتنسيقات تتناسب بدقة مع سير عمل المستخدم، مثل القوائم أو الجداول.
الذكاء الاصطناعي الحيرة: نهج شفاف للبحث التوليدي
يبرز الذكاء الاصطناعي Perplexity AI بسبب كيفية إظهاره لعمله بشكل علني. في حين أن جوجل وبينج غالبًا ما يمزج بين التوليف والمصادر بطرق تخفي ما يحدث خلف الكواليس، فإن Perplexity يجعل اقتباساته واضحة ومرئية، وغالبًا ما يسردها حتى قبل الرد الذي تم إنشاؤه. بالنسبة للمستخدمين، يعني ذلك إحساساً أفضل بمصدر المعلومات. أما بالنسبة لمحترفي GEO، فهي فرصة غير عادية لمشاهدة أنماط الاسترجاع والاقتباس في الوقت الفعلي تقريباً.
من الناحية الوظيفية، لا يحتفظ Perplexity بفهرس دائم خاص به. ففي كل مرة يتم فيها إدخال استعلام، يُجري بحثًا جديدًا، وعادةً ما يستقي من Bing وGoogle. ثم يتم تقييم المرشحين ليس فقط على أساس الملاءمة، ولكن أيضًا على صفات مثل الوضوح والسلطة وما إذا كان يمكن استخراج المحتوى بسهولة في إجابة.
ما مكافأة الحيرة
- الإجابات المباشرة: مقاطع موجزة تعيد صياغة الاستفسار وتعطي ردًا واضحًا مقدمًا.
- وضوح الكيان: الأسماء، والشركات، والمنتجات، والمنتجات، والأماكن التي يتم استدعاؤها مباشرة، مدعومة بروابط مخطط أو سياق.
- مصداقية المؤلف: السير الذاتية، ووثائق التفويض، وإشارات الثقة التنظيمية تضيف وزناً.
- الدعم المرئي: غالبًا ما ترتبط الرسوم البيانية والصور التي توضح المفاهيم بمعدلات اقتباس أعلى.
- الاتساع الدلالي: الصفحات التي تغطي زوايا متعددة من الاستعلام دون أن تنحرف عن الموضوع تظهر بشكل أكثر موثوقية.
على سبيل المثال، إذا سأل شخص ما "ما الذي يفصل GPT-4 عن GPT-5؟"، فمن المرجح أن يستخدم Perplexity صفحة تحتوي على هذه العبارة بالضبط في العنوان، متبوعة مباشرةً بشرح قصير. عادةً ما يخسر المحتوى الطويل أو الإجابات المدفونة في عمق الصفحة.
ما أهمية ذلك بالنسبة لتوقعات البيئة العالمية
ما يجعل Perplexity قيمة من منظور التحسين هو شفافيته. يمكنك أن ترى المصادر التي يتم الاستشهاد بها بالضبط، ومقارنتها بمصادرك، وتعديلها بسرعة. إذا تم استبعاد صفحتك، عادةً ما يكون من السهل تحديد السبب: ربما تكون إجابتك غير قابلة للاستخراج بما فيه الكفاية، أو أن كياناتك غير محددة بوضوح، أو أن أحد المنافسين نظم نفس المحتوى بشكل أكثر وضوحًا.
وتتمثل قواعد اللعبة هنا في تصميم المحتوى كوحدات إجابة معيارية: ابدأ بإجابة واضحة وقابلة للاقتباس، ثم توسع بالتفاصيل الداعمة والأمثلة والمرئيات. أضف السياق للكيانات، وعزز إشارات الثقة من خلال السير الذاتية والتفاصيل التنظيمية.
قد لا ينافس موقع Perplexity Google من حيث عدد الزيارات الخام، ولكن يمكن القول إنه أفضل مختبر لاختبار ما ينجح في البحث التوليدي. يمكن بعد ذلك نقل الأنماط التي تؤكدها هنا إلى منصات أقل شفافية بكثير.
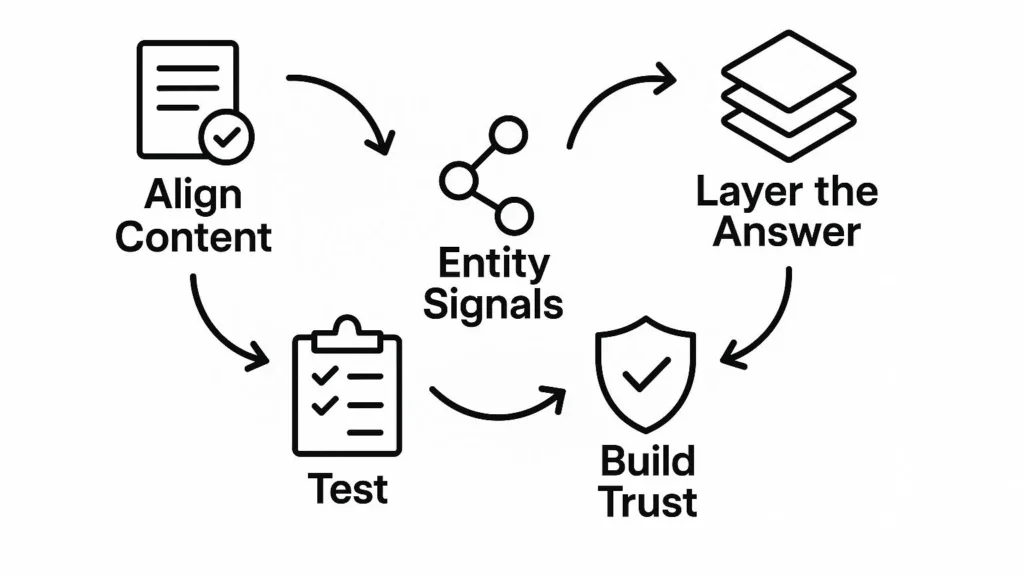
استراتيجية GEO للحيرة
إن Perplexity ليس دليلًا سلبيًا للنتائج - إنه مسترجع نشط يقوم بالترشيح بقوة من أجل الوضوح والدقة والثقة. لكسب الاستشهادات هنا، يجب بناء المحتوى بطريقة يمكن للنظام أن يرفعها مباشرةً إلى إجاباته المركبة.
محاذاة المحتوى مع إطار الاستعلام
- ردد السؤال في عنوان أو عنوان فرعي.
- اتبعها على الفور بإجابة قصيرة وتوضيحية.
- اجعل الجملة الافتتاحية قابلة للاستخدام بمفردها، دون الحاجة إلى سياق إضافي.
مثال على ذلك: يجب أن يقابل استعلام مثل "ما هو النفق الكمي؟" برأس قسم يكرر المصطلح وتعريف من جملة واحدة يمكن أن يكون مستقلاً في مخرجات Perplexity.
تعزيز إشارات الكيانات
- قم بتسمية الكيانات الرئيسية (الشركات، والأشخاص، والمنتجات، والأماكن) وربطها بوضوح.
- استخدم ترميز المخطط حيثما أمكن.
- أحيط الكيانات بتفاصيل سياقية حتى يسهل تمييزها.
عندما تقدم صفحات متعددة إجابات متشابهة، فإن الصفحة التي تنشئ شبكة دلالية أقوى من الكيانات عادةً ما تفوز.
طبقات الإجابة عن الأعماق المختلفة
- ابدأ بشرح واضح ومقتبس.
- أضف توسعة متوسطة المستوى تعطي فارقاً بسيطاً.
- ادعمها بالرسوم البيانية أو الأمثلة أو مربعات الحقائق من أجل استكشاف أعمق.
يمنح هذا النمط Perplexity خيارات متعددة للسحب منها، اعتمادًا على ما إذا كان النظام يريد مقتطفًا قصيرًا أو مقطعًا أكثر تفصيلاً.
بناء الثقة في الصفحة
- قم بتضمين السير الذاتية للمؤلفين وبيانات الاعتماد والمعلومات التنظيمية.
- اذكر المصادر الموثوقة مباشرةً.
- استهدف الظهور إلى جانب أقرانك ذوي السمعة الطيبة في نفس مجموعة الإجابات.
على الرغم من أن Perplexity لا يكشف عن "درجة E-E-A-A-T" صريحة، إلا أنه يتصرف باستمرار كما لو كانت إشارات السلطة مهمة.
الاختبار والتكيف باستمرار
نظرًا لأن Perplexity يجعل اقتباساته مرئية، فإنه يوفر حلقة تغذية راجعة نادرة في بحث الذكاء الاصطناعي. يمكنك تتبع الصفحات التي تظهر على السطح، ومقارنتها بصفحاتك، وتحسين بنية المحتوى حتى يحقق أداءً أفضل. يمكن بعد ذلك تطبيق هذا التعلم نفسه على أنظمة أقل شفافية مثل وضع الذكاء الاصطناعي من جوجل أو Bing Copilot.
مقارنة تكتيكات توقعات البيئة العالمية عبر منصات الذكاء الاصطناعي
يعمل كل نظام بحث توليدي على نفس الدورة الواسعة: جمع النتائج، وتنقيحها، واستخدامها لتوليد إجابة. لكن الروافع الأكثر أهمية ليست متسقة. ما يجعلك تستشهد في محرك ما قد لا يهم في محرك آخر.
فكّر في الأمر بهذه الطريقة:
- إذا لم يكن من الممكن استرجاع المحتوى الخاص بك، فلن يدخل في المحادثة أبدًا.
- إذا لم يكن بالإمكان رفعه بشكل نظيف، فلن يصبح مادة تأريض.
- إذا كانت تفتقر إلى السلطة، فيمكن تخطيها حتى لو كانت ذات صلة.
إليك كيفية تكديس اللاعبين الرئيسيين.
ميزات الذكاء الاصطناعي من جوجل
تعمل "النظرة العامة" و"وضع الذكاء الاصطناعي" من Google على توسيع نطاق استعلامات المستخدم إلى زوايا متعددة، حيث يتم السحب من نتائج الويب وبيانات الرسم البياني المعرفي والفهارس الرأسية. تميل الصفحات التي تجيب عن عدة جوانب لسؤال ما، في مقتطفات واضحة وقابلة للاستخراج، إلى الظهور في أغلب الأحيان. تحمل تغطية الكيانات القوية وعلامات المصداقية وزناً إضافياً.
مايكروسوفت بينج كوبيلوت
يدمج Copilot بين نظام الترتيب الكلاسيكي لـ Bing مع التوليف التوليدي. ولكي يتم أخذ المحتوى الخاص بك في الاعتبار، يجب أن يحقق المحتوى الخاص بك أداءً جيدًا في كل من البحث بالكلمات الرئيسية والبحث الدلالي. وبمجرد دخوله إلى المجمع، فإن المقاطع القصيرة والمحددة النطاق: القوائم أو التعريفات أو التفسيرات الموجزة - تتمتع بأفضل فرصة للاقتباس. تساعد إشارات مثل الحداثة وترميز المخطط وموثوقية المؤلف في ترجيح كفة الميزان.
الدردشةGPT مع التصفح
يُنشئ ChatGPT استعلامات البحث الخاصة به ويسحب مجموعة صغيرة من الصفحات في وقت التشغيل. وهذا يعني أن النجاح هنا يعتمد على كونها متاحة على الفور وسهلة المعالجة، وليس على سلطة الترتيب على المدى الطويل. إن HTML النظيف، وسرعة التحميل السريع، والعناوين أو العناوين التي تعكس الطريقة التي يصوغ بها المستخدمون أسئلتهم، كل ذلك يحسّن من احتمالات إدراجها.
حيرة الذكاء الاصطناعي
يقوم Perplexity بإجراء عمليات بحث جديدة لكل استعلام ويعرض مصادرها بشكل مفتوح. نظرًا لأنه لا يحتفظ بفهرس دائم، يجب أن يكون المحتوى الخاص بك سريعًا وقابلًا للزحف وسهل التحليل على الآلات. الإجابات المباشرة والمكتفية بذاتها وسياق الكيانات القوي هي الأفضل أداءً. شفافيتها تجعلها بيئة اختبار مفيدة لاستراتيجيات GEO، حتى لو كان حجم الزيارات أقل من جوجل.
مرجع توقعات البيئة العالمية السريع حسب المنصة
| المنصة | نهج الاسترجاع | إعداد الفهرس | الأهم من ذلك كله | كيف تظهر الاستشهادات | لماذا يتم استبعاد الصفحات |
| نظرة عامة على الذكاء الاصطناعي من Google ووضع الذكاء الاصطناعي | يقسم الاستعلامات إلى متغيرات متعددة (كلمات مفتاحية، تضمينات، كيانات) ويبحث عبر مصادر مختلفة | فهرس الويب الكامل من Google بالإضافة إلى الرسم البياني المعرفي وقواعد البيانات الرأسية | تغطية العديد من زوايا الاستفسار، وكتابة مقاطع نظيفة يمكن رفعها، وإظهار الخبرة الموضوعية والثقة | الروابط المضمنة أو اللوحات الجانبية أو بطاقات "المزيد من المصادر" | عدم تطابق الصفحات مع الاستعلامات الفرعية، أو صعوبة استخراج المقاطع أو ضعف إشارات الثقة/السلطة |
| بينج كابتن طيار | المسار المزدوج: استرجاع الكلمات المفتاحية (BM25) إلى جانب البحث في المتجهات الدلالية، متبوعًا بإعادة ترتيب المقاطع | فهرس الويب الكامل لـ Bing | وجود قوي للكلمات الرئيسية والإشارات الدلالية، والأقسام القابلة للاستخراج (القوائم، والتعريفات القصيرة)، والحداثة، وترميز المخطط | الحروف العلوية المضمنة المتصلة ببطاقات المصدر | العرض المتأخر يخفي النص، والمحتوى المدفون في عمق الصفحات الطويلة، وترميز الكيان/المؤلف المفقود |
| حيرة الذكاء الاصطناعي | المكالمات في الوقت الحقيقي للمحركات الخارجية (Bing/Google بشكل أساسي) وجلب عناوين URL انتقائية | لا يوجد مؤشر دائم - يعتمد على واجهات برمجة التطبيقات الخارجية | صفحات قابلة للزحف وسريعة التحميل، وإجابات موجزة تعكس الاستعلام، وكيانات محددة جيدًا | المصادر مدرجة في المقدمة، ثم يتم الاستشهاد بها في الرد | حظر Robots.txt، وتأخير نص جافا سكريبت الثقيل، وبطء استجابة الخادم |
| الدردشةGPT مع التصفح | تقوم LLM بإعادة صياغة الاستعلام، وإرساله إلى Bing (وأحيانًا إلى Google)، وجلب بعض عناوين URL، وتحليلها مباشرةً | لا يوجد مؤشر ثابت | عناوين وعناوين واضحة ومباشرة دلاليًا، وصفحات يسهل الوصول إليها على الفور، وبنية HTML نظيفة | اقتباسات مضمنة أو في النهاية، وغالباً ما تكون جزئية | عنوان URL غير مطلوب، أو المحتوى محجوب أو بطيء جداً، أو النص لا يمكن تحليله بسهولة |
اختتام تقسيم المنصة
عندما تقارن بين منصات بحث الذكاء الاصطناعي الرئيسية جنبًا إلى جنب، يتضح لك أنها لا تلعب بنفس القواعد. يوسّع جوجل الشبكة بتوسعات الاستعلام، ويعتمد بينج على أنظمة التصنيف الراسخة لديه، ويعرض بيربليسيتي مصادره علانية، ويعتمد تشات جي بي تي على كل ما يمكنه جلبه في الوقت الحالي. لكل منها توازنه الخاص في الاسترجاع والتصفية والتركيب، وهذا يعني أن أدوات التحسين تختلف في كل منها.
ومع ذلك، يظهر تسلسل مشترك. يجب أن يكون المحتوى قابلاً للعثور عليه أولاً، وإلا فلن يدخل في الاعتبار. ثم يجب أن يكون منظمًا بطريقة يمكن اقتباسه مباشرة، حتى يتمكن النظام من إدخاله في إجابة دون جهد. وأخيرًا، يجب أن يحمل ما يكفي من إشارات السلطة والثقة للنجاة من التصفية. نقاط التحقق هذه موجودة في كل مكان، حتى لو تغير الترجيح من محرك إلى آخر.
والنقطة المهمة الأخرى هي أن أياً من هذه المنصات لا تعمل على استعلام حرفي واحد. فجميعها تعيد صياغة ما كتبه المستخدم لإظهار المقاصد ذات الصلة. لا يأتي النجاح من ملاحقة الكلمات المفتاحية الفردية بقدر ما يأتي من بناء محتوى يمكن أن يخدم مجالاً كاملاً من الأسئلة ذات الصلة.
الأسئلة المتداولة
يركز تحسين محركات البحث التقليدية بشكل كبير على استهداف الكلمات الرئيسية وترتيب الصفحات. تذهب محركات بحث الذكاء الاصطناعي إلى أبعد من ذلك - فهي تعيد صياغة الاستعلامات، وتستخدم التضمينات للعثور على محتوى مرتبط دلالياً، وتعتمد على نماذج اللغة لتوليد الإجابات. وهذا يعني أن النجاح لا يعتمد على الكلمات المفتاحية فحسب، بل يعتمد أيضاً على البنية والوضوح والسلطة.
RAG هو نظام يسحب فيه نموذج الذكاء الاصطناعي معلومات جديدة من فهرس قبل توليد استجابة. بدلاً من الاعتماد فقط على ما تعلمه أثناء التدريب، فإنه يؤسس مخرجاته على البيانات الخارجية الحالية. وهذا يقلل من الهلوسة ويجعل الإجابات أكثر موثوقية.
لا يقوم جوجل بتشغيل استعلام واحد فقط. فهو يقسّم السؤال الأصلي إلى عدة استفسارات فرعية لتغطية مختلف المقاصد المحتملة. إذا كان المحتوى الخاص بك يطابق العديد من هذه الزوايا وكان مكتوبًا بطريقة يمكن اقتباسها بسهولة، فستكون لديك فرصة أكبر في أن يتم إدراجك.
غالبًا ما تكون مشكلة هيكلية. فالصفحات التي يتم تحميلها ببطء، أو تعتمد بشكل كبير على جافا سكريبت للمحتوى الأساسي، أو تدفن الحقائق الأساسية في فقرات طويلة، أو تفتقر إلى إشارات واضحة للمؤلف/المؤسسة يصعب على أنظمة الذكاء الاصطناعي استخلاصها. حتى لو كان الموضوع ذا صلة، فقد يتم تخطيها.
لا تزال السلطة مهمة - فقط بطرق مختلفة قليلاً. يمكن أن تكون إشارات الثقة مثل بيانات اعتماد المؤلف، والتغطية الموضعية المتسقة، والروابط الخلفية القوية، وترميز المخطط، حاسمة عندما يكون لدى النظام مقاطع متعددة للاختيار من بينها.
تُظهر الحيرة اقتباساتها مقدمًا، مما يسهل اختبار ما يصلح. تميل الإجابات القصيرة والمباشرة تحت عناوين واضحة، وربط الكيانات القوية، والصفحات سريعة التحميل إلى الأداء الأفضل. كما أنه يكافئ الوضوح والدقة على الصفحات الطويلة المثقلة بالسرد.



