AI-powered search doesn’t run on a single blueprint. Yes, most platforms rely on some mix of vector retrieval, ranking models, and large language model outputs, but the way they stitch those parts together can look very different. Those differences shape everything from speed to transparency to how useful the answers feel.
For anyone working in generative engine optimization (GEO), understanding these distinctions isn’t optional. What gets your content surfaced inside Google’s AI features may not register at all in Perplexity or Bing, and vice versa. Knowing the mechanics behind each system is the first step to making your content discoverable.
This article takes a closer look at the architecture of the most visible players. We’ll examine how they build their pipelines, the choices they make around indexing and synthesis, and what those choices mean for the visibility of your brand.
Why Retrieval-Augmented Generation Matters
The backbone of today’s AI search tools is a design known as retrieval-augmented generation, or RAG. It’s essentially a way to patch two of the biggest flaws in language models: their habit of making things up and the fact that their training data goes stale. By tying generation to live or frequently updated sources, RAG helps keep answers accurate and relevant.
The process usually unfolds like this: the system takes a user’s question and converts it into one or more dense vectors. Those vectors are compared against an index of stored embeddings that represent content across formats: text, video, images, or even structured data. The system then pulls a candidate set of matches. Before passing them to the language model, a more resource-heavy ranker often reorders those candidates by relevance. The top slices of that set become the grounding context for the model’s response.
The advantage is clear: instead of pulling only from months-old training data, the model can reason over information fetched moments earlier. For GEO professionals, this means visibility comes down to two things. First, your content has to be findable in the embedding space through rich metadata and clear semantic signals. Second, it has to be written in a way the model can easily digest: structured, factual, and clean. Miss either requirement, and your content won’t make it into the final generated answer.
Semantic Indexing as the Foundation
Traditional search engines relied on inverted indexes that matched exact words. AI-driven search flips that model by storing information as dense vectors inside a database. Each document is represented not by keywords alone, but by numerical patterns that capture its meaning in a high-dimensional space. That’s why a query and a passage can still connect even if they don’t share a single word in common.
Modern systems also lean into multi-modal indexing. Instead of treating text as the only entry point, they create embeddings for images, audio, tables, and other formats, all linked back to a single document ID. In practice, this means an infographic or a product photo on your site could surface as evidence in a generative answer, even if the surrounding text isn’t competitive.
For GEO, the lesson is straightforward: semantic clarity wins. Content should spell out ideas in plain language, not bury them in jargon. Images need meaningful alt text and captions. Audio and video should have transcriptions and metadata that describe what’s inside. The richer and clearer your signals, the better chance you have of being pulled into the retrieval layer.
Blending Lexical and Semantic Retrieval
Even though vector search has changed the game, most AI search systems don’t rely on it alone. They use a hybrid approach that combines the strengths of both semantic and traditional keyword-based retrieval.
Lexical methods still shine when precision is needed – think of rare terms, product IDs, or exact names. Semantic methods, on the other hand, excel at capturing broader meaning, surfacing content that might not match word-for-word but aligns with the intent. By running both approaches side by side and then applying a reranker to refine the results, platforms can get the best of both worlds.
In practice, this often looks like a BM25 keyword search running alongside a nearest-neighbor vector search. The outputs are merged, normalized, and reordered by a contextual model that weighs relevance at the passage level. The outcome is a pool of results that balances precision with recall.
For GEO specialists, the takeaway is clear: you can’t abandon the fundamentals. Classic keyword optimization is still important for lexical matching, while semantic coverage determines whether you show up in the embedding index. Success comes from doing both well, not choosing one over the other.

How We Approach GEO at Nuoptima
At Nuoptima, we understand that search has shifted. It’s no longer just about climbing blue links – it’s about being visible in AI-powered environments where answers are generated, not just listed. That’s why we’ve built our approach around both classic SEO foundations and strategies tailored for generative search.
Here’s how we make it work:
- SEO + GEO combined: We handle everything from technical audits and site fixes to content strategies designed to surface in AI Overviews, Bing Copilot, and Perplexity.
- Measurable results: Our clients have collectively raised over $500m, with an average 3.2x return on ad spend and consistent traffic growth across competitive sectors.
- High-volume, high-quality content: We publish more than 800k words per month, blending AI-driven insights with expert human editing so content is both machine-readable and engaging for real people.
- Global reach: Our international SEO work ensures brands can scale across languages and regions with the right structure and metadata in place.
- Proven trust: Over 70 industry leaders count on us to deliver sustainable growth, not just short-term wins.
Our focus is simple: we engineer relevance. By making content clear, structured, and credible, we help brands earn their place in the answers AI platforms generate – and stay there as the search landscape evolves.
Google’s AI Search: Overviews and AI Mode
Google’s entry into generative search builds directly on top of its long-standing infrastructure, blending large language models with the search systems it has refined for decades. Instead of treating AI answers as a bolt-on feature, Google has woven them into the core of Search.
When you type a query, Google doesn’t just run a single lookup. It breaks the query into multiple angles – variations that capture different potential intents. These spin-off queries are sent across multiple sources at once: the main web index, the Knowledge Graph, YouTube transcripts, Shopping feeds, and other specialized databases.
The results from each source are gathered, filtered, and deduplicated before being handed off to a Gemini-based model. In AI Overviews, the model synthesizes a concise summary and places it at the top of the results page with citations woven in. In AI Mode, the experience shifts into a conversational flow, where context persists across turns and the system can call for additional information mid-discussion.
For GEO, the implication is big: Google rewards content that can satisfy multiple angles of a query. If your page only covers one slice, you risk being left out. Pages that address related intents, present clear, self-contained passages, and demonstrate authority stand a much better chance of being surfaced in synthesis.
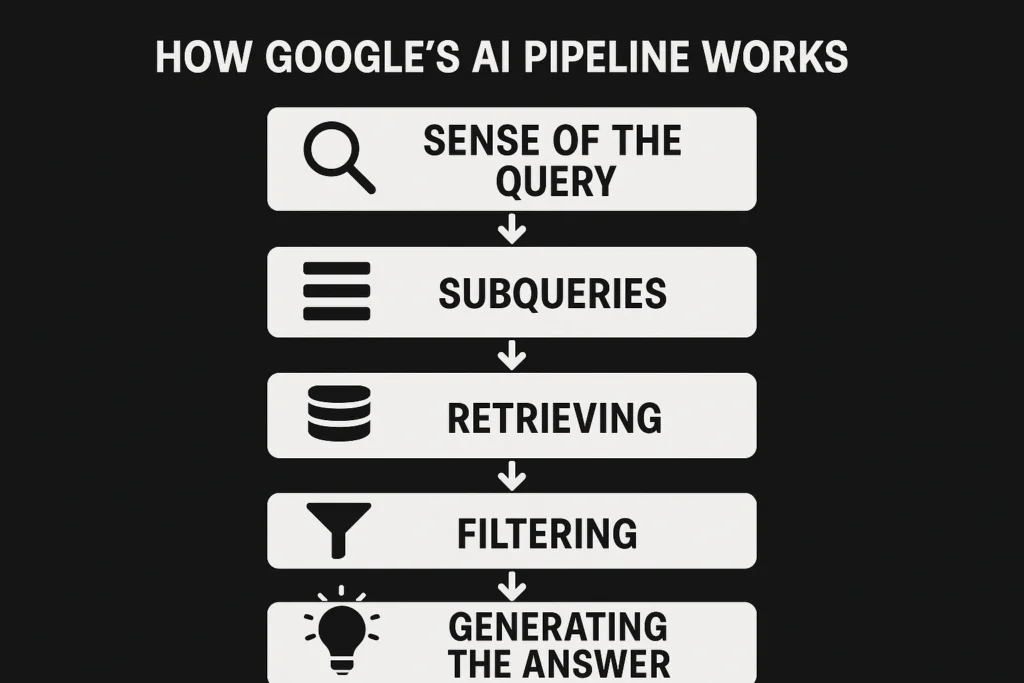
How Google’s AI Pipeline Works Behind the Scenes
While the interface feels new, Google’s AI Overviews and AI Mode are powered by processes built deep into its search stack. Based on what’s visible from patents, public statements, and observed behavior, the system seems to follow five key stages:
1. Making Sense of the Query
The first step is parsing the query in multiple ways. Google generates different representations: a lexical version for exact word matching, dense embeddings for semantic retrieval, entities mapped against the Knowledge Graph, and a task signal that defines what type of answer is needed – a comparison, a how-to, or a summary. It also handles basics like language detection and spelling corrections. Not every query qualifies for an AI answer; sensitive or high-stakes searches are often filtered out.
2. Expanding with Subqueries
If the query is eligible, Google branches it into multiple subqueries designed to capture hidden intent.
Take the query “how to start a vegetable garden at home” as an example. It could branch into:
- “beginner vegetable gardening tips”
- “vegetable planting calendar by season”
- “best soil for vegetable gardens”
- “tools needed for home gardening”
Each subquery is routed to the most relevant source, whether that’s the web index, YouTube transcripts, Shopping feeds, or Maps.
3. Retrieving from Multiple Sources
Each subquery is run through the appropriate retrieval engine. For web results, this could mean BM25 keyword matching alongside vector-based semantic search. Other sources rely on different methods — graph traversal for Knowledge Graph facts, multimodal embeddings for videos or images. Documents are often broken into smaller chunks with their own embeddings, improving recall at a more granular level.
4. Merging and Filtering
The returned results are pooled together, duplicates removed, and filters applied. Google looks at trust signals (E-E-A-T), freshness, safety checks, and whether passages are clean enough to be quoted directly. If the system can’t find extractable snippets, those pages are less likely to be cited, even if they’re relevant.
5. Generating the Answer
Finally, a Gemini-based model takes the top passages and weaves them into a synthesized response. Citations may appear inline, in side panels, or as expandable lists of sources. AI Overviews aim for concise, single-pass summaries, while AI Mode allows for longer, multi-turn conversations, retrieving more evidence as needed.
What this means for GEO: Success depends on covering multiple related intents, writing passages that stand alone as clear, extractable answers, and signaling authority. Pages that meet those criteria have a far better chance of being surfaced and cited in Google’s AI results.
ChatGPT: A Model Without Its Own Index
Unlike Google or Bing, ChatGPT doesn’t maintain a standing web index of its own. The core model is trained on a massive, frozen dataset, but when browsing is enabled it depends on live retrieval. When a user asks a question, ChatGPT reformulates it into a search-style query and sends it through external engines, most often Bing and occasionally Google. From there, it gets back a handful of links, fetches the content in real time, and processes that material directly to build its answer.
This setup has important consequences. Whether your content appears has nothing to do with historical authority or long-term ranking. It depends entirely on whether your pages can be retrieved and parsed at the moment the query is made. If your site is blocked in robots.txt, bogged down by slow loading, hidden behind client-side rendering, or written in a way that’s too opaque for the model to parse, it won’t make it into the synthesis stage at all.
For visibility in this environment, the playbook looks much closer to classic SEO basics. Pages need to be lightweight, technically crawlable, and semantically transparent. In practice, that means: clean HTML, fast performance, no blockers to crawlers, and content written in plain, extractable language. When the model reaches for real-time context, those are the sites it can actually use.
Bing Copilot: Search Meets Generative AI
Bing’s Copilot shows what happens when a mature search engine is fused with a conversational model. Instead of discarding decades of ranking systems, Microsoft has repurposed Bing’s index and then added a GPT-style layer to summarize results. The effect is that all the familiar SEO basics still decide which pages make it into the pool, while clarity and structure determine which ones actually get cited in answers.
Here’s how the pipeline typically plays out.
Step 1: Interpreting What You Asked
When a query comes in, Copilot doesn’t just read it at face value. It creates multiple parallel interpretations: one for traditional keyword matching, one for semantic similarity via embeddings, and another that maps entities to Bing’s Knowledge Graph. It also tags the intent of the request: whether it’s a factual lookup, a how-to guide, or a product comparison, and uses that signal to decide which vertical sources to lean on. Unlike Google’s habit of fanning queries out broadly, Bing keeps things tighter, filtering early.
Step 2: Mixing Keyword and Semantic Matches
Copilot runs both exact-match search and semantic search in tandem. Keyword matching works best for unique identifiers like SKUs or brand names, while semantic search pulls in conceptually related passages. The results are blended, normalized, and filtered for freshness and site quality. Because Bing’s index is already curated, what comes through tends to be solid, crawlable, and canonical. This is why simple hygiene: clear canonical signals, fast load times, clean HTML, still matters so much here.
Step 3: Choosing the Right Passages
At this stage, Bing applies a more advanced reranker that looks at query and passage together. It no longer treats pages as monolithic; instead, it scores individual sections. The model prefers passages that are concise, scoped, and easy to reuse – a definition, a short explanation, or a structured block like a table. Deduplication also kicks in here, removing near-identical content and ensuring diversity. Trust and authority matter in tie-breaks, so a well-structured passage from a reputable domain beats the same idea from a weaker site.
Step 4: Turning Passages Into an Answer
The top passages are handed to a GPT-class model, which generates a summary grounded in that evidence. Copilot’s generation is tightly constrained: it’s built to paraphrase and synthesize, not invent. In longer chats, it can call for additional retrieval when new angles come up, but the overall pattern stays grounded in what was actually retrieved. For site owners, this means your best bet is to phrase claims cleanly and in scope, so the model can lift them without juggling multiple fragments.
Step 5: Showing Results and Enabling Actions
Once the synthesis is complete, Copilot presents the answer with citations attached. These often appear as inline superscripts or short lists under the response. Unlike Google’s broader Overviews, Copilot tends to keep its citation list small and precise, since grounding happens at the passage level. What sets it apart is its deep integration into Microsoft 365: answers can move straight into Word, Excel, or Teams. That makes structured formats: tables, lists, checklists, especially powerful, since they flow seamlessly into user workflows.
Why Pages Sometimes Don’t Make It
A page might rank in Bing’s standard results but never show up in Copilot’s citations. The usual reasons aren’t topical, but structural: slow client-side rendering that delays text, cluttered page layouts that confuse extraction, or long stretches of narrative that hide the key claim. Weak author or entity signals can also hurt when competing passages are otherwise equal.
The GEO playbook for Bing Copilot is to think traditional SEO plus passage-level engineering:
- Compete on both lexical and semantic retrieval.
- Present claims in short, extractable passages.
- Strengthen entity and author signals.
- Keep pages up to date with versioned or dated content.
- Offer content in formats that map neatly into user workflows, like lists or tables.
Perplexity AI: A Transparent Approach to Generative Search
Perplexity AI stands out because of how openly it shows its work. While Google and Bing often blend synthesis and sourcing in ways that hide what’s happening behind the scenes, Perplexity makes its citations clear and visible, often listing them even before the generated response. For users, that means a better sense of where information is coming from. For GEO professionals, it’s an unusual chance to watch retrieval and citation patterns play out almost in real time.
Functionally, Perplexity doesn’t keep its own permanent index. Each time a query is entered, it runs a fresh search, usually drawing from Bing and Google. The candidates are then weighed not just on relevance, but also on qualities like clarity, authority, and whether the content can be easily extracted into an answer.
What Perplexity Rewards
- Direct answers: Concise passages that restate the query and give a clear response upfront.
- Entity clarity: Names, companies, products, and places called out directly, supported with schema or context links.
- Author credibility: Bios, credentials, and organizational trust signals add weight.
- Visual support: Diagrams and images that illustrate concepts often correlate with higher citation rates.
- Semantic breadth: Pages that cover multiple angles of a query without drifting off-topic surface more reliably.
For example, if someone asks “What separates GPT-4 from GPT-5?”, Perplexity is more likely to use a page that features that exact phrase in a heading, followed immediately by a short explanation. Long-winded content or answers buried deep in the page usually lose out.
Why It Matters for GEO
What makes Perplexity valuable from an optimization perspective is its transparency. You can see exactly which sources get cited, compare them against your own, and adjust quickly. If your page is excluded, it’s usually easy to spot the reason: maybe your answer isn’t extractable enough, or your entities aren’t clearly defined, or a competitor structured the same content more cleanly.
The playbook here is to design content as modular answer units: start with a crisp, quotable response, then expand with supporting details, examples, and visuals. Add context for entities, and strengthen trust signals through bios and organizational detail.
Perplexity may not rival Google in raw traffic, but it’s arguably the best laboratory for testing what works in generative search. The patterns you confirm here can then be carried over to platforms that are far less transparent.
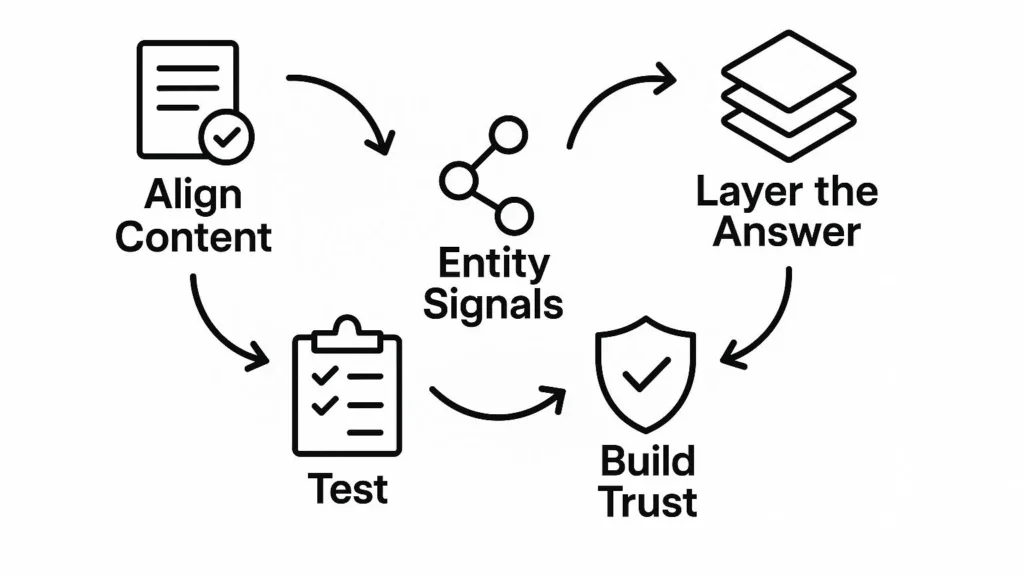
GEO Strategy for Perplexity
Perplexity isn’t a passive directory of results – it’s an active retriever that filters aggressively for clarity, precision, and trust. To earn citations here, content has to be built in a way that the system can lift directly into its synthesized answers.
Align Content With the Query Frame
- Echo the question in a heading or subheading.
- Follow immediately with a short, declarative answer.
- Make the opening sentence usable on its own, without needing extra context.
Example: A query like “What is quantum tunneling?” should be met with a section header repeating the term and a one-sentence definition that could stand alone in Perplexity’s output.
Strengthen Entity Signals
- Clearly name and link key entities (companies, people, products, places).
- Use schema markup where possible.
- Surround entities with contextual details so they’re easy to distinguish.
When multiple pages provide similar answers, the one that creates a stronger semantic network of entities usually wins.
Layer the Answer for Different Depths
- Begin with a sharp, quotable explanation.
- Add a mid-level expansion that gives nuance.
- Support with diagrams, examples, or fact boxes for deeper exploration.
This style gives Perplexity multiple options to pull from, depending on whether the system wants a short snippet or a more detailed passage.
Build Trust Into the Page
- Include author bios, credentials, and organizational information.
- Cite credible sources directly.
- Aim to appear alongside reputable peers in the same answer set.
Even though Perplexity doesn’t expose an explicit “E-E-A-T score,” it consistently behaves as if authority signals matter.
Test and Adapt Continuously
Because Perplexity makes its citations visible, it offers a feedback loop rare in AI search. You can track which pages surface, compare them to your own, and refine content structure until it performs better. This same learning can then be applied to less transparent systems like Google AI Mode or Bing Copilot.
Comparing GEO Tactics Across AI Platforms
Every generative search system runs on the same broad cycle: gather results, refine them, and use them to generate an answer. But the levers that matter most aren’t consistent. What gets you cited in one engine may not matter in another.
Think of it this way:
- If your content can’t be retrieved, it never enters the conversation.
- If it can’t be lifted cleanly, it won’t become grounding material.
- If it lacks authority, it may be skipped even if relevant.
Here’s how the main players stack up.
Google’s AI Features
Google’s Overviews and AI Mode expand user queries into multiple angles, pulling from web results, Knowledge Graph data, and vertical indexes. Pages that answer several facets of a question, in clear and extractable snippets, tend to surface most often. Strong entity coverage and credibility markers carry extra weight.
Microsoft Bing Copilot
Copilot marries Bing’s classic ranking system with generative synthesis. To be considered, your content must do well in both keyword search and semantic search. Once inside the pool, short, scoped passages: lists, definitions, or concise explanations – have the best chance of being quoted. Signals like freshness, schema markup, and author trustworthiness help tip the scales.
ChatGPT with Browsing
ChatGPT generates its own search queries and pulls a small set of pages at runtime. That means success here depends on being instantly available and easy to process, not on long-term ranking authority. Clean HTML, fast load speeds, and titles or headings that mirror the way users phrase their questions all improve the odds of being included.
Perplexity AI
Perplexity runs fresh searches for each query and shows its sources openly. Because it doesn’t keep a standing index, your content needs to be fast, crawlable, and easy for machines to parse. Direct, self-contained answers and strong entity context perform best. Its transparency makes it a useful test environment for GEO strategies, even if the traffic volume is smaller than Google’s.
Quick GEO Reference by Platform
| Platform | Retrieval Approach | Index Setup | What Matters Most | How Citations Appear | Why Pages Get Excluded |
| Google AI Overviews & AI Mode | Splits queries into multiple variants (keywords, embeddings, entities) and searches across different sources | Full Google web index plus Knowledge Graph and vertical databases | Covering several query angles, writing clean passages that can be lifted, demonstrating topical expertise and trust | Inline links, side panels, or “more sources” cards | Pages don’t match subqueries, passages are hard to extract, or trust/authority signals are weak |
| Bing Copilot | Dual-track: keyword retrieval (BM25) alongside semantic vector search, followed by passage reranking | Bing’s full web index | Strong keyword presence and semantic signals, extractable sections (lists, short definitions), freshness, and schema markup | Inline superscripts connected to source cards | Delayed rendering hides text, content buried deep in long pages, missing entity/author markup |
| Perplexity AI | Real-time calls to external engines (mainly Bing/Google) and selective URL fetching | No standing index – relies on external APIs | Crawlable and fast-loading pages, concise answers that mirror the query, well-defined entities | Sources listed upfront, then cited inline within the response | Robots.txt blocking, heavy JavaScript delaying text, slow server response |
| ChatGPT with Browsing | LLM reformulates the query, sends it to Bing (sometimes Google), fetches a few URLs, and parses them directly | No persistent index | Clear, semantically direct titles and headings, instantly accessible pages, clean HTML structure | Citations inline or at the end, often partial | URL not requested, content blocked or too slow, or text not easily parsed |
Wrapping Up the Platform Breakdown
When you compare the major AI search platforms side by side, it’s clear they don’t play by the same rules. Google widens the net with query expansions, Bing builds on its established ranking systems, Perplexity shows its sources openly, and ChatGPT depends on whatever it can fetch at the moment. Each has its own balance of retrieval, filtering, and synthesis, and that means the optimization levers are different for each one.
Even so, a shared sequence emerges. Content has to be findable first, or it won’t even enter consideration. It then needs to be structured in a way that can be quoted directly, so the system can slot it into an answer without effort. Finally, it must carry enough authority and trust signals to survive filtering. Those checkpoints exist everywhere, even if the weighting changes from engine to engine.
The other important point is that none of these platforms work off a single literal query. They all reformulate what the user typed to surface related intents. Success comes less from chasing individual keywords and more from building content that can serve an entire field of related questions.
Frequently Asked Questions
Traditional SEO focused heavily on keyword targeting and page ranking. AI search engines go further — they reformulate queries, use embeddings to find semantically related content, and rely on language models to generate answers. That means success depends not only on keywords but also on structure, clarity, and authority.
RAG is a system where an AI model pulls fresh information from an index before generating a response. Instead of relying only on what it learned during training, it grounds its output in current, external data. This reduces hallucinations and makes answers more reliable.
Google doesn’t just run one query. It breaks the original question into multiple sub-queries to cover different possible intents. If your content matches several of those angles and is written in a way that can be easily quoted, you have a higher chance of being included.
It’s often a structural issue. Pages that load slowly, rely heavily on JavaScript for core content, bury key facts in long paragraphs, or lack clear author/organization signals are harder for AI systems to extract. Even if the topic is relevant, they may get skipped.
Authority still matters – just in slightly different ways. Trust signals like author credentials, consistent topical coverage, strong backlinks, and schema markup can be decisive when the system has multiple passages to choose from.
Perplexity shows its citations upfront, making it easier to test what works. Short, direct answers under clear headings, strong entity linking, and fast-loading pages tend to perform best. It rewards clarity and precision over long, narrative-heavy pages.



