Publishing content does not guarantee visibility. Every search engine and LLM applies aggressive content filtering to decide what earns crawl budget, indexation, and AI citations. This is a search reality, not a security firewall.
Most brands ignore these invisible barriers and lose pipeline. We use a technical SEO and GEO lens to navigate these seven layers of content-based filtering across Google and answer engines. Start with the only filter you fully control: indexation directives.
Key Takeaways
- Content filtering is the series of decisions search and AI engines make about which pages earn crawl budget, indexation, and citations, not a single switch.
- Indexation is the one filter you fully control: use noindex, rel=canonical, and 301/410 codes to cut index bloat, but never mix conflicting signals.
- Crawl budget is a resource allocation decision, so cleanse sitemaps to canonical URLs, strengthen internal linking, and block crawl traps with robots.txt.
- Modern engines filter out thin, derivative content, so original data, answer completeness, and strong E-E-A-T are what earn citations.
- Content filtering (a restrictive search/security barrier) is the opposite of content-based filtering (a recommender system on platforms like LinkedIn and YouTube).
1. Master Indexation Directives and Consolidation Signals
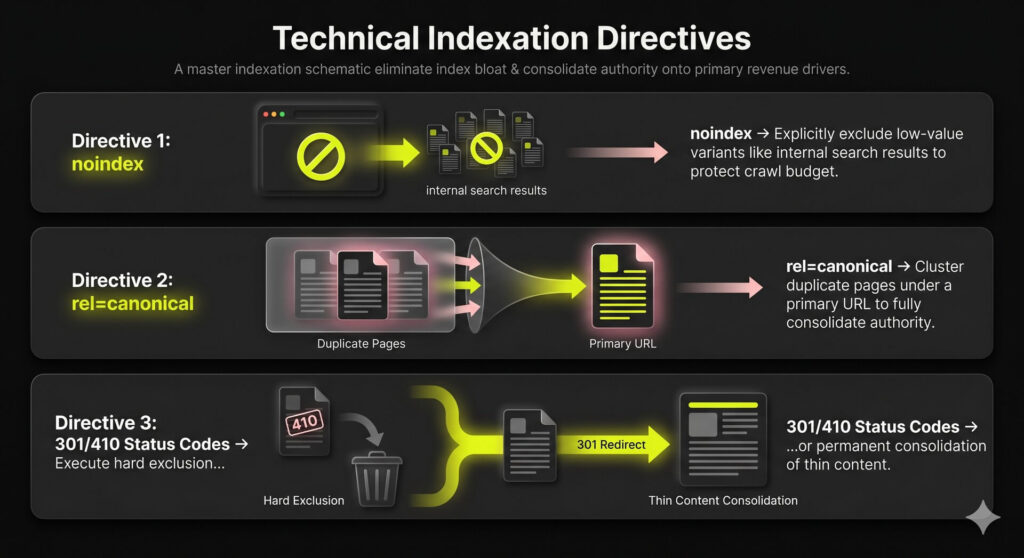
Indexation is a deliberate inclusion decision, not a reward for publishing. Use explicit directives to eliminate index bloat and prevent low-value pages from de-prioritizing your revenue drivers.
Control site architecture with these signals:
- noindex: Exclude low-value variants like internal search results to protect crawl budget.
- rel=canonical: Cluster duplicates under a primary URL to consolidate authority.
- 301/410 Status Codes: Execute hard exclusion or permanent consolidation.
Mixed signals waste crawl and trigger unpredictable indexing outcomes, which can be mitigated by deploying advanced automation SEO frameworks. Precise directives prevent self-sabotage, ensuring search engines prioritize your highest-leverage, conversion-ready assets according to the ultimate indexing playbook.
2. Prioritize Crawl Budget via Architectural Hygiene
Crawl is a resource allocation decision. Bloated faceted navigation, orphaned pages, and parameter-heavy URLs force crawlers to waste energy on digital junk instead of revenue-generating content.
Treat crawl budget like site processing latency. Lightweight hygiene ensures search engines prioritize high-value pages over low-value variants:
- Cleanse XML Sitemaps: Include only canonical, index-worthy URLs.
- Strengthen Internal Linking: Reinforce priority pages to signal authority.
- Block Crawl Traps: Use Robots.txt carefully to restrict access to infinite URL spaces.
This ensures key pages are discovered and refreshed reliably without wasting budget on architectural noise.
3. Manage Canonicalization to Stop Signal Fragmentation
Duplicates aren’t penalized; they’re clustered. Search engines group similar pages and select a representative URL, stripping your control over which page wins. Fragmentation typically stems from:
- Tracking parameters (UTMs)
- Trailing slashes and protocol variants (HTTP/HTTPS)
- Thin location or category templates
Surrendering this selection to an algorithm dilutes authority and confuses AI discovery. Prevent ranking dilution by implementing a rigid canonical strategy and pointing all internal links to your primary revenue driver. Consolidating thin content into one authoritative asset ensures ranking signals and AI citations aggregate onto a single, conversion-ready URL.
4. Overcome Content Filtering with Unique Entity Signals
Modern search systems apply aggressive content filtering to throttle mediocre, derivative, or thin pages. Even indexed content remains invisible if it lacks originality or trust signals. Scaled programmatic templates and redundant “me-too” posts are filtered out of the active ranking layer.
To earn citations in AI answers and traditional SERPs, upgrade your content with:
- Answer completeness: Clear definitions, steps, and constraints.
- Evidence assets: Proprietary data, case outcomes, and original frameworks.
- Strong E-E-A-T: Proven authorship and specific proof points.
Investing in evidence-backed pillars over volume publishing ensures your brand becomes the cited, authoritative answer.
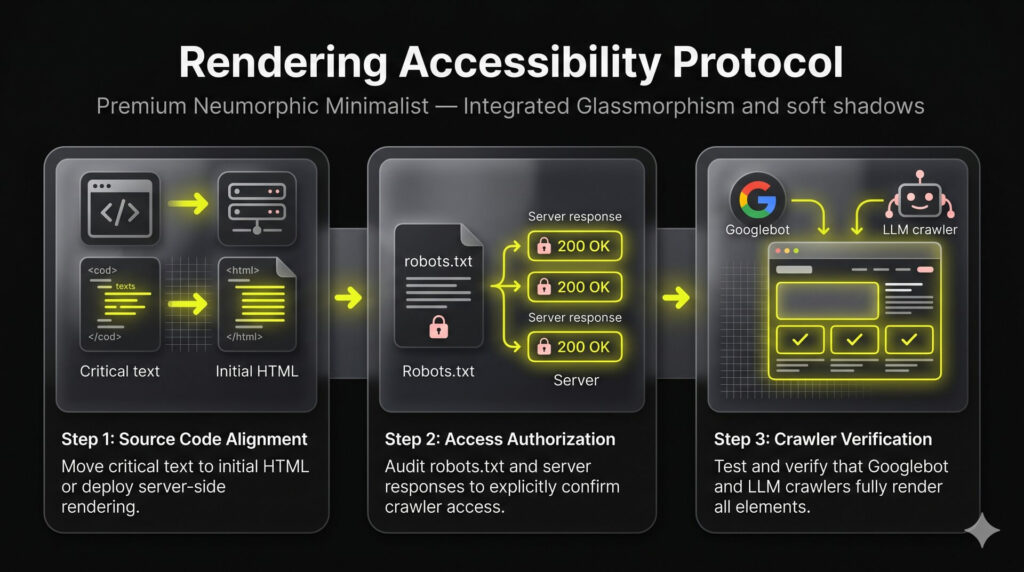
5. Ensure Technical Fetchability and Rendering Consistency
Pages appearing perfect in browsers can remain invisible to search engines through silent exclusion. Technical barriers or client-side rendering often trigger unintended content filtering. Common blockers include login gates, blocked JavaScript, and content hidden by user interactions. If rendering delays exceed crawler timeouts, your information remains undetected.
Prioritize these technical controls to ensure citation:
- Move critical content to initial HTML or use server-side rendering.
- Audit robots.txt and server responses to confirm crawler access.
- Verify that Googlebot and LLM crawlers render all elements.
This prevents indexation gaps where published pages never become readable assets.
6. Align Content Architecture with the AI Citation Layer
AI engines no longer “rank” pages. They perform precise content filtering by selecting specific passages and entities to synthesize answers. Most B2B content remains invisible because insights are not extractable for retrieval engines. This occurs when pages lack structured sections, direct definitions, or clear entity authority.
To capture citations, brands must deploy the following controls:
- Citation blocks with crisp definitions and numbered steps
- Verifiable claims backed by concrete data or statistics
- Strengthened entity signals via schema and consistent internal linking
Visit NUOPTIMA’s GEO service page to engineer measurable AI citation growth and dominate generative search results.
7. Distinguish Content Filtering from Content-Based Filtering
Marketing teams often conflate two technically opposite systems. Content filtering is a restrictive security protocol used to block access for compliance. Conversely, content-based filtering is a recommender system that suggests items based on metadata and features.
Channels like LinkedIn and YouTube use the latter to prioritize visibility. Your strategy must account for both search indexation and platform recommendation filters. Precise terminology in briefs prevents conceptual errors that lead to misaligned tooling and wasted budget. Distinguishing indexation control from algorithmic suggestion ensures your brand becomes the cited answer across traditional and generative search engines.
How to Build an Advanced URL Policy and Content Filtering Workflow
Transform technical concepts into a quarterly execution sequence to maintain site health and AI visibility. Move from inventory to iteration using this structured roadmap.
Step 1: Build a URL Inventory
Export indexed URLs from Google Search Console and your CMS sitemaps. Run a technical crawl to identify parameter-heavy URLs and orphaned pages. Tag every URL by template type: blog, category, location, help docs, internal search, or parameter pages.
Step 2: Classify Templates via Content Filtering
Sort templates into three strategic buckets. Use Index and Rank for strategic landing pages and evergreen guides. Use Crawl but Don’t Index for utility pages and low-intent variants. Use Don’t Crawl for obvious crawl traps or infinite URL spaces.
Step 3: Apply Filter Controls
Apply rel=canonical tags and consolidate internal links for duplicate content. Deploy noindex tags for necessary low-value pages to protect indexation quality. Prune sitemaps to exclusively feature index-worthy canonical URLs.
Step 4: Validate and Tune the Allowlist
Monitor for false positives where valuable pages are accidentally filtered. Review Crawl Stats and Indexing reports to resolve contradictory signals and ensure a healthy crawl budget.
Step 5: Add the GEO Layer
Inject extractable answers and entity clarity into Index and Rank pages. Format key insights into citation-ready blocks so LLMs can easily retrieve and cite your data.
Secure your search authority. Partner with nuoptima.com for a technical GEO strategy to make your brand the definitive answer.
NUOPTIMA provides specialized GEO support to help brands engineer their content for these emerging generative citation layers.
Where this fits in your MSP growth system
This is one piece of how NUOPTIMA makes MSPs and cybersecurity firms the provider buyers find on Google and in AI search. See how it connects to MSP content marketing and MSP SEO, or get your free MSP lead forecast to see exactly where your firm shows up across ChatGPT, Gemini, and Perplexity today.